© 2026 NervNow™. All rights reserved.

 ByNN Desk
ByNN Desk
Meet Gemini 3.1 Flash-Lite, Google’s Most Cost-Efficient AI Model Yet
Available in preview today on Google AI Studio and Vertex AI, the new model is priced at $0.10 per million input tokens and claims a 2.5x speed improvement over its predecessor, aimed squarely at high-volume developer workloads.
Available in preview today on Google AI Studio and Vertex AI, the new model is priced at $0.10 per million input tokens and claims a 2.5x speed improvement over its predecessor, aimed squarely at high-volume developer workloads.
Google on Tuesday launched Gemini 3.1 Flash-Lite, the newest and most cost-efficient model in its Gemini 3 series, available in preview to developers via the Gemini API in Google AI Studio and to enterprises through Vertex AI. The model is positioned as Google’s answer to high-frequency, high-volume AI workloads where cost and speed matter more than raw capability, use cases like translation, content moderation, UI generation, and real-time simulations.
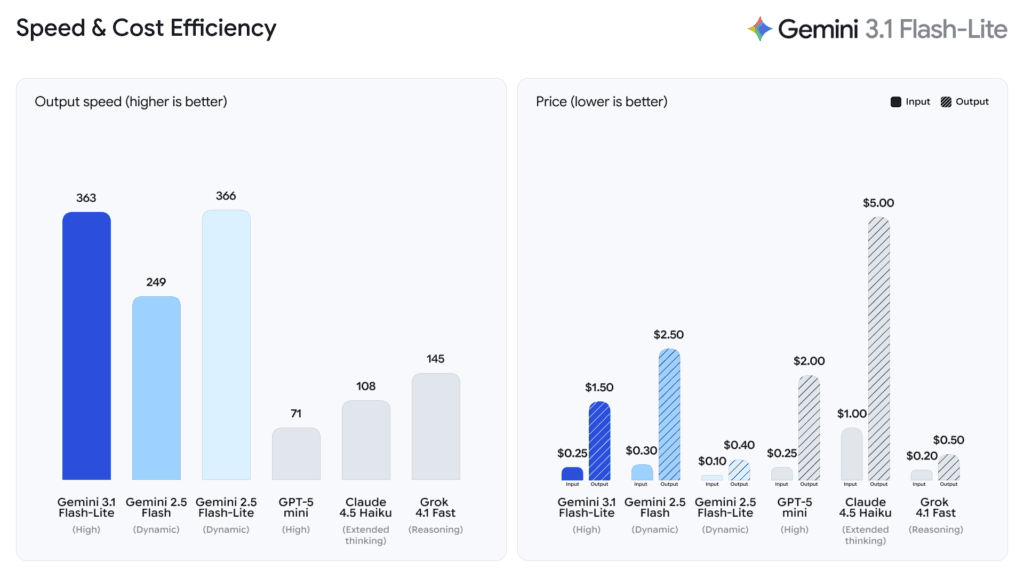
Priced at $0.25 per million input tokens and $1.50 per million output tokens, the model is significantly cheaper than larger Gemini 3 offerings. According to the Artificial Analysis benchmark cited by Google, 3.1 Flash-Lite is 2.5 times faster in Time to First Answer Token and delivers a 45% increase in output speed compared to 2.5 Flash, while maintaining similar or better quality. On the Arena.ai leaderboard, it achieves an Elo score of 1,432 and posts 86.9% on the GPQA Diamond benchmark and 76.8% on MMMU Pro — results that, Google notes, surpass larger Gemini models from prior generations including 2.5 Flash.
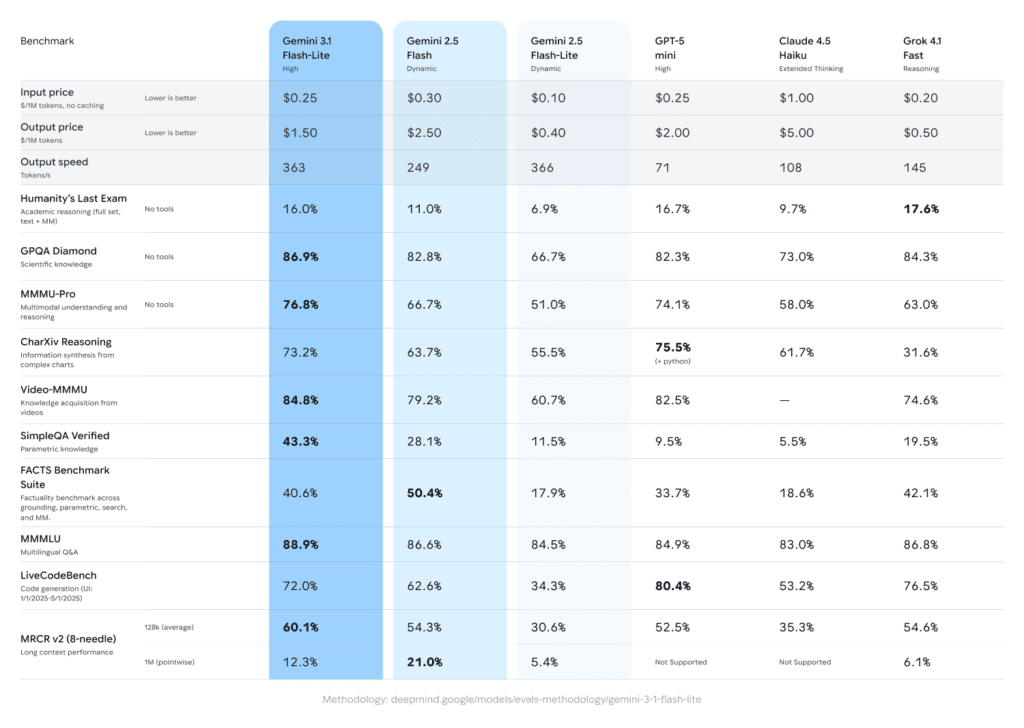
One notable feature is built-in thinking level controls, available as standard in both AI Studio and Vertex AI. Developers can adjust how much the model thinks for a given task, a lever designed specifically for managing high-frequency workloads where inference cost compounds at scale. For simpler tasks such as bulk translation or content filtering, less thinking reduces cost and latency. For more complex workloads like multi-step instructions, dashboard generation, or simulation, the model can be pushed to reason more deeply. Google says early-access testers noted the model can handle complex inputs with the precision of a larger-tier model while maintaining instruction adherence.
ALSO READ: Nano Banana 2 is Google’s Fastest Image AI Yet
Companies including Latitude, Cartwheel, and Whering are among the early users cited by Google, though the announcement provides no specific performance or deployment details for those deployments. The model launches into a competitive tier that includes GPT-5 Mini, Claude 4.5 Haiku, and Grok 4.1 Fast, all targeting a similar price-performance bracket for developer workloads at scale.
This article is based entirely on the announcement published on Google’s official blog (The Keyword) on March 3, 2026. NervNow has not independently verified performance claims.
MORE ON GOOGLE
Google Launches AI Professional Certificate on Coursera
Alphabet’s Intrinsic Robotics Unit Officially Joins Google
Google Publishes 2026 Responsible AI Report Amid Growing Scrutiny
Google Pledges $15 Billion to Build India’s First Full-Stack AI Hub
Sundar Pichai Meets PM Modi at India AI Summit; Google Signals Deeper AI Partnership with India