© 2026 NervNow™. All rights reserved.
 ByChetanya Puri
ByChetanya Puri- On
How Model Routers Cut AI Costs by Up to 70% for Enterprises
Enterprises use multiple AI models, but costs and risks rise without control. Model routers route tasks to the right model, improving efficiency and governance.
- Read Time18 mins
Analysis · Explainer
What Is a Model Router and Why Enterprises Running Multiple AI Tools Need One
As companies deploy several AI models simultaneously, a new infrastructure layer has quietly become essential: the model router. Here is what it does, why it exists, and what it means for enterprise AI strategy.
N
NervNow Editorial
May 2026 · 8 min read
37%
of enterprises now run 5+ AI models in production
30-70%
cost reduction reported with intelligent routing
60-80%
of LLM spend goes to tasks that don’t need the most expensive model
Most large enterprises today are not running one AI model. They are running several, often without a coherent plan for which model handles what. A legal team may use one tool for contract review. A customer service function uses another for response drafting. An internal IT helpdesk runs a third. The finance team has adopted a fourth. Each deployment happened independently, often driven by a department head rather than a central technology decision.
This is now the dominant pattern. According to a 2025 survey of enterprise CIOs published by Andreessen Horowitz, 37 percent of respondents are now running five or more AI models in production, up from 29 percent the year prior. The primary driver is not vendor diversification for its own sake. It is model differentiation by use case: different models genuinely perform better on different tasks.
The problem this creates is a management and cost problem. When every team routes every request to whichever model they happen to have access to, regardless of whether that model is the right tool for the task, the enterprise ends up overpaying significantly, introducing unnecessary risk, and building a sprawling AI infrastructure with no central visibility.
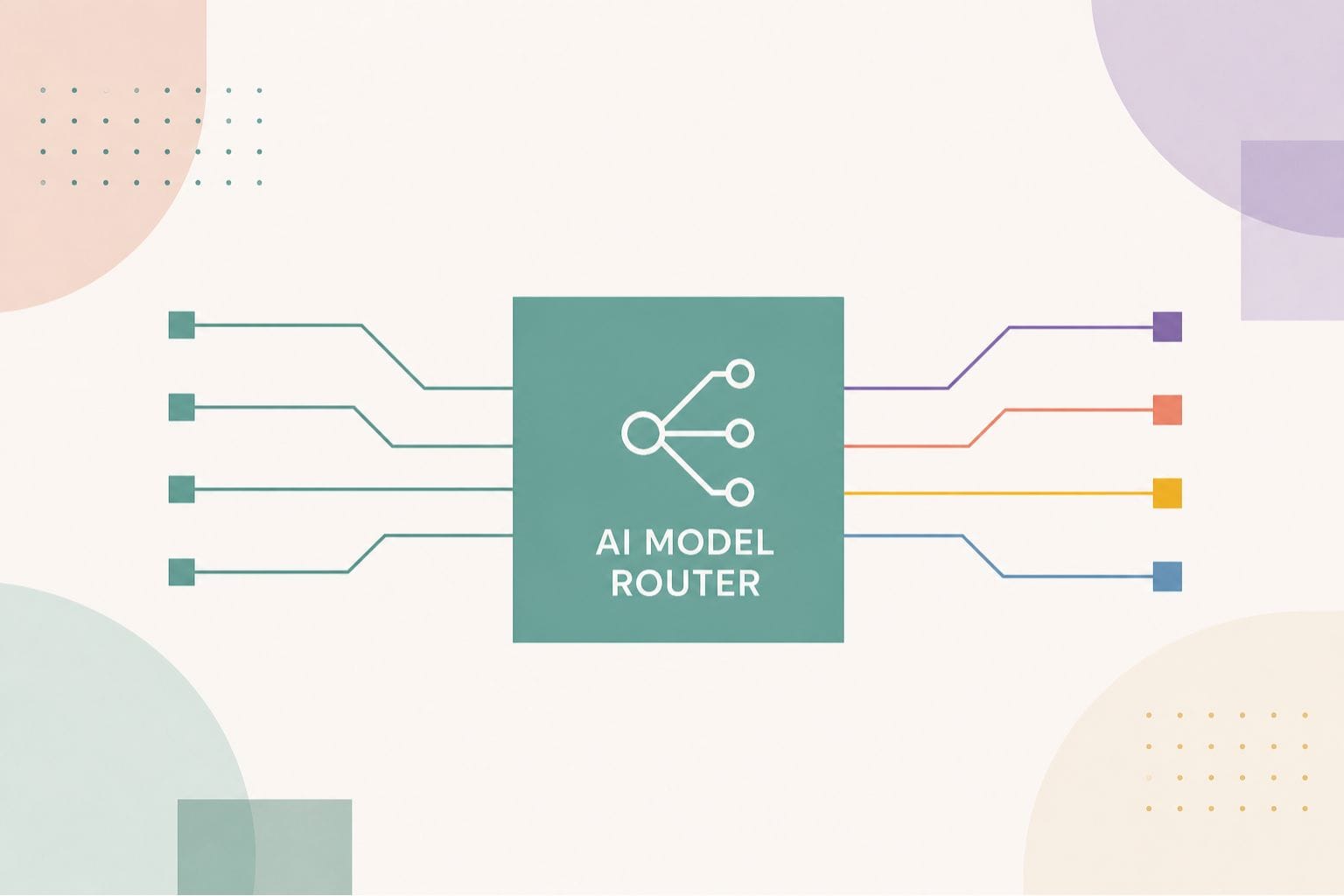
A model router is the infrastructure layer designed to solve this.
The Core ConceptWhat a Model Router Actually Does
A model router sits between your applications and your AI model providers. When a request comes in, a query, a prompt, a task, the router analyzes it and decides which model in your available pool is the most appropriate one to handle it, then sends the request there automatically.
How to think about it
Consider how a well-run law firm assigns work. A senior partner does not draft every client email. Routine correspondence goes to a junior associate. Complex litigation strategy goes to the senior partner. Document review goes to a paralegal. The work is matched to the appropriate level of expertise and cost. A model router applies the same logic to AI requests, automatically, in real time, at scale.
The router evaluates each incoming request across several dimensions: the complexity of the task, the response speed required, the cost of using each available model, and any data sensitivity or compliance rules that apply. Based on these criteria, it selects the optimal model and routes accordingly.
A simple FAQ from a customer service portal does not need a large, expensive frontier model. A routine HR query does not require the same model deployed for your legal document analysis. The router makes these distinctions automatically, without requiring your teams to manually switch between tools.
Why It ExistsThe Problem That Created the Need
Enterprise AI cost structures have become difficult to manage. Research across multiple organizations indicates that between 60 and 80 percent of LLM spending goes toward tasks that do not actually require the most capable or most expensive models. Research from UC Berkeley and Canva, cited in MindStudio’s published routing analysis, found that intelligent routing delivers an 85 percent cost reduction while maintaining 95 percent of frontier model performance on the same tasks.
Most enterprises are running their highest-cost AI model as the default for everything. That is the equivalent of flying a senior consultant in to answer questions that a well-written FAQ could handle.
NervNow AnalysisBeyond cost, there is a reliability problem. In 2025, every major LLM provider experienced at least one significant service disruption. For an enterprise that has built a customer-facing application on a single model from a single provider, a provider outage means the application goes down. A model router with fallback configuration resolves this: when a primary model is unavailable, the router automatically redirects requests to an alternative, without any change to application code and without visible disruption to users.
There is also a governance problem. When AI requests flow directly from dozens of applications to multiple external providers, there is no central audit trail, no single point of visibility, and no mechanism to enforce data handling rules across the entire AI estate. A model router, properly implemented, centralizes that control.
How Routing Decisions Are MadeThe Logic Inside the Router
Routing decisions are not arbitrary. They follow one of three broad approaches, and enterprise implementations often combine all three.
Rule-based routing is the simplest form. The enterprise defines explicit rules: all requests tagged as legal document analysis go to Model A; all customer service queries go to Model B; all code generation tasks go to Model C. This approach is transparent and predictable, but it requires someone to maintain and update the rules as task types evolve.
Classifier-based routing uses a lightweight model, significantly cheaper than your production models, to analyze each incoming request and predict which of your available models is best suited to handle it. The classifier might assess the complexity, the domain, the required reasoning depth, and the sensitivity of the content, then output a confidence score for each available model. The request is sent to the highest-scoring option.
Cost-aware routing adds a financial layer: the router monitors real-time spend and can shift traffic based on budget thresholds. If monthly AI spend is approaching a defined ceiling, the router can automatically route a larger proportion of requests to lower-cost models without any manual intervention.
Enterprise Use CasesWhere This Matters in Practice
⚖️
Legal and Compliance Operations
A general counsel’s office handling hundreds of contracts monthly may use a premium model for complex multi-jurisdiction clause analysis while routing standard NDA reviews and template generation to a faster, cheaper model. The router handles the triage. Legal teams work from a single interface without knowing, or needing to know, which model processed which document.
🏦
Financial Services and Regulated Industries
In banking or insurance, certain data cannot leave domestic infrastructure. A model router can enforce this as a hard rule: any request containing customer financial data is routed only to on-premise or regionally compliant models, while general-purpose queries route to cloud-hosted frontier models. Compliance becomes architectural rather than procedural.
🛎️
Large-Scale Customer Operations
A company running AI-assisted customer service across thousands of daily interactions can route routine transactional queries, order status, return policies, standard troubleshooting, to a fast, inexpensive model, while escalated or complex complaints are sent to a more capable one. Quality is maintained where it matters; cost is reduced where it does not.
🏭
Manufacturing and Supply Chain
Enterprises running AI across procurement, demand forecasting, and shop floor operations have meaningfully different latency and accuracy requirements for each. Routing allows a single AI infrastructure to serve all three without the highest-stakes use case subsidizing the lowest-stakes one.
Why This Is a Strategic Infrastructure Decision, Not a Technical One
CXOs considering AI infrastructure often underestimate how consequential the routing layer is. The router is not merely a cost optimization tool. It is the point at which AI governance becomes enforceable at scale.
A properly configured model router centralizes authentication across all AI providers, enforces role-based access controls that determine which teams can use which models, maintains a unified audit trail across every AI interaction in the enterprise, and enforces budget limits at the team or department level. These are not features that matter only to the technology team. They are capabilities that matter to the CFO, the Chief Risk Officer, the CISO, and anyone responsible for regulatory compliance.
There is also a vendor lock-in dimension that deserves attention. Enterprises that have built AI applications by routing requests directly to a single provider’s API are, in practice, locked to that provider. Migrating to a different model requires rewriting integration code, re-testing outputs, and re-tuning prompts across every application. A model router abstracts this: the application speaks to the router, not to the provider. Switching a model underneath requires a configuration change, not a re-engineering effort.
The lock-in risk in plain terms
What to Ask Before Deploying
One CIO surveyed in the Andreessen Horowitz 2025 enterprise AI report described the problem directly: all the prompts in their agentic workflows had been tuned for a specific provider’s model. Each contained its own set of instructions. Switching models would require re-engineering and re-validating every one of them. That is the kind of technical debt that accumulates silently when routing is not planned for from the outset.
The Questions That Matter for Senior Decision-Makers
For CXOs evaluating whether their organization needs a model router, or assessing the routing layer already in place, the relevant questions are not primarily technical. They are operational and strategic.
Does your organization have visibility into how much each department is spending on AI, broken down by model and use case? If the answer is no, you do not have the cost transparency that responsible AI deployment requires. A router with cost analytics provides it.
If your primary AI provider had a four-hour outage tomorrow, what would happen to customer-facing applications? If the answer is that they would go down, your architecture does not have the resilience that enterprise infrastructure should. A router with fallback configuration addresses this directly.
When sensitive data, customer records, financial information, personnel files, enters your AI systems, do you know with certainty which model processed it and where that processing occurred? If not, you have a compliance exposure that data protection regulations, including India’s Digital Personal Data Protection Act, will eventually surface. A router with data routing rules and a unified audit trail closes that gap.
Finally: who in your organization currently has the authority to approve access to a new AI model? If that decision is happening informally, at department level, without central oversight, then shadow AI, employees using models the enterprise has not formally sanctioned, is likely already present in your operations. A router with access controls makes AI adoption governed rather than ungoverned.
Context for Indian EnterprisesWhy This Is Particularly Relevant in India Right Now
Indian enterprises are adopting AI at a pace that is outrunning their infrastructure planning. The combination of the Digital Personal Data Protection Act, emerging sectoral AI guidelines from RBI and SEBI, and the operational reality that many Indian enterprises serve customers across connectivity-variable environments makes the routing layer more consequential here than in markets where AI adoption has been more gradual and more regulated from the start.
Data residency requirements, the obligation to keep certain categories of data within Indian borders, cannot be managed manually at scale. The only reliable way to enforce them across an enterprise AI estate with multiple models and multiple use cases is through a routing layer that applies residency rules as a technical constraint, not a policy aspiration.
For Indian CXOs, the model router is not a future consideration. It is infrastructure that should be present before, not after, AI deployment reaches the scale at which governance failures become expensive.
Editorial note: This article is an explainer based on publicly available research, published enterprise AI surveys, and documented infrastructure patterns. Cost figures cited reflect reported ranges across multiple organizations and should not be treated as guaranteed outcomes for any specific deployment. Vendor names are referenced for illustration only; NervNow has no commercial relationship with any AI infrastructure provider mentioned in this piece.
Sources
- Andreessen Horowitz – “How 100 Enterprise CIOs Are Building and Buying Gen AI in 2025” (February 2026)
- MindStudio – “What Is an AI Model Router? Optimize Cost Across LLM Providers” (February 2026)
- MindStudio – “Best AI Model Routers for Multi-Provider LLM Cost Optimization” (February 2026)
- Requesty – “Intelligent LLM Routing in Enterprise AI: Uptime, Cost Efficiency, and Model Selection”
- Maxim AI – “Best LLM Gateway to Design Reliable Fallback Systems for AI Apps” (March 2026)
- Maxim AI – “Best LLM Gateways in 2025: Features, Benchmarks, and Builder’s Guide” (February 2026)
- IDC – “Beyond LLMs: Why AI Strategy Now Requires Multi-Model, Multimodal, and Multi-Agent Architectures” (April 2026)
- Fluid AI – “One AI Model Won’t Fit All: Why Enterprise Workflows Need Multi-LLM and Contextual Interop” (April 2025)
- TrueFoundry – “What Is an LLM Gateway and How Does It Work?” (February 2026)
- Portkey – “The Complete Guide to LLM Observability for 2026” (January 2026)
More Deep Dives
Analysis
Are Indian Enterprises Paying Full Price for a Half-Built AI Product?
AnalysisHow to Evaluate AI Vendor Claims: A Technical Guide for CTOs and AI Leaders
AnalysisWhy Every AI Chatbot Seems to Give the Same Advice? The Artificial Hivemind Effect, Explained
AnalysisPrompts, RAG, or Fine-Tuning? The AI Stack Decision Most Teams Get Wrong
Tags

Chetanya Puri
Chetanya Puri is a Senior Machine Learning Engineer at CluePoints in Brussels, Belgium, where his work spans machine learning and natural language processing. Previously, he was an Early Stage Researcher and PhD candidate at KU Leuven, focused on scalable machine learning under limited data conditions and time-series analysis. He has held industry research roles at Philips Research and Tata Consultancy Services, with a technical background spanning Bayesian methods, NLP, and time-series analysis.